우리는 웹 사이트를 보거나 메일을 보내거나 받을 때 애플리케이션을 사용한다. 웹 브라우저나 메일 프로그램 등과 같은 애플리케이션은 사용자가 하고 싶은 일을 할 수 있도록 도와준다. 애플리케이션은 서비스와 요청하는 측과 서비스를 제공하는 측으로 나뉘는데 서비스를 요청하는 측은 클라이언트(Client), 제공하는 측을 서버(Server)라고 한다.
웹 브라우저나 메일 프로그램은 클라이언트, 웹 서버 프로그램과 메일 서버 프로그램은 서버가 된다. 이러한 애플리케이션은 응용 계층에서 동작한다. 응용 계층에서는 클라이언트의 요청을 전달하기 위해 서버가 이해할 수 있는 메세지(데이터)로 변환하고 전송 계층으로 전달하는 역할을 한다.
웹 브라우저나 메일 프로그램은 클라이언트, 웹 서버 프로그램과 메일 서버 프로그램은 서버가 된다. 이러한 애플리케이션은 응용 계층에서 동작한다. 응용 계층에서는 클라이언트의 요청을 전달하기 위해 서버가 이해할 수 있는 메세지(데이터)로 변환하고 전송 계층으로 전달하는 역할을 한다.
이처럼 클라이언트와 서버가 통신하려면 응용 계층의 프로토콜을 사용해야 한다. 프로토콜에는 웹 사이트를 볼 때는 HTTP, 파일을 전송할 때는 FTP, 메일을 보낼 때는 SMTP, 메일을 받을 때는 POP3 등이 있다. 또한, 네트워크에서 컴퓨터나 네트워크에 붙여진 이름을 기반으로 IP 주소를 알아내는 것을 이름 해석(Name resolution)이라고 하는데, 이를 위해 DNS를 사용한다.
결국, 응용 계층은 각각의 애플리케이션에 대응되는 데이터를 전송하는 역할을 한다.
웹 서버의 구조
인터넷에서 핵심적인 역할을 하고 있는 WWW(World Wide Web)은 줄여서 웹(Web)이라고 불린다. WWW는 HTML, URL, HTTP라는 세 가지 기술이 사용된다.
HTML(Hyper Text MarkUp Language)은 웹 페이지에서 문장 구조나 문자를 꾸미는 태그를 사용하여 작성하는 마크업(MarkUp)언어 이다. 제목이나 목록같은 문장 구조를 지정하거나 이미지, 동영상 파일을 보여 줄 때도 태그를 사용한다. 또한, 하이퍼텍스트(Hypertext)는 하이퍼링크(Hyperlink)를 사용해 아이콘이나 버튼 등에 있는 링크를 클릭하면 다른 사이트로 이동할 수 있다. 이동한 사이트에서는 html 파일이나 이미지 파일이 웹 서버에서 전송된다.
클라이언트(웹 브라우저)는 웹 사이트를 보기 위해 서버(웹 서버 프로그램)의 80번 포트를 사용하여 HTTP 통신을 한다. 다음 그림과 같이 클라이언트에서 HTTP 요청(Request)을 보내고 서버에서 HTTP 응답(Response)을 반환한다.
클라이언트가 데이터를 요청할 때는 요청 정보(GET 등), 파일 이름, 버전 등을 서버에 전송한다. 그러면 서버는 응답으로 요청을 정상적으로 처이했다는 메세지(OK 등) 정보를 반환하고 payment.html을 클라이언트로 보낸다.
HTTP 버전에 대해 잠시 살펴보면
HTTP 1.0 버전: 요청을 보낼 때마다 연결했다가 끊는 작업을 반복
HTTP 1.1 버전: Keepalive라는 기능이 추가되어서 연결을 한 번 수립하면 데이터 교환을 마칠 때까지 유지하고, 데이터 교환을 모두 끝내면 연결을 끊는 구조이다. 또한, 요청도 순서대로 처리하는 특징이 있다.
HTTP 2.0 버전: HTTP 1.1 버전은 요청을 순서대로 응답을 반환하는 특징을 보완(이전 요청이 길어지면 다음 요청의 처리가 느려짐)
DNS 서버 구조
기본적으로 컴퓨터(서버)에는 IP주소가 있어서 인터넷을 통해 웹 서버에 접속하여 웹 사이트를 볼 수 있다. 하지만, 우리는 웹 브라우저 주소 창에 URL(Uniform Resource Locator)를 통해 웹 사이트에 접속한다.
컴퓨터(서버)에 접속하려면 IP 주소를 입력해야 하는데 사람들은 www.github.com를 입력해서 들어간다. 이처럼 URL을 IP주소로 변환해서 해당 웹 사이트에 들어갈 수 있게 해주는 서비스(시스템)가 DNS 이다. 따라서, IP 주소인 222.235.255.255와 같이 기억하기 어려운 숫자들보다는 URL을 사용하면 더 쉽게 기억할 수 있을 것이다. DNS 서버의 이름해석(Name Resolution) 기능을 사용하면 가능하다.
www.github.com에서 www는 호스트 이름(서버 이름)을 나타내고 github.com은 컴퓨터나 네트워크를 식별하기 위해 사용하는 도메인 이름이다.
DNS 서버는 전 세계에 흩어져 있고 모두 계층적으로 연결되어 있다. 그래서 첫 번째 DNS 서버가 도멘인의 IP 주소를 모르르 경우 연결되어 있는 다른 DNS 서버에 요청을 해서 IP 주소를 알아낸다.
메일 서버 구조
메일을 송수신 하기 위해서 사용해야 하는 포로토콜은 두 가지가 존재한다. 메일을 보내는 데 사용되는 프로토콜은 SMTP(Simple Mail Transfer Protocol)고, 메일을 받는 데 사용되는 프로토콜은 POP3이다. STMP는 25번, POP3는 110번 포트를 사용한다.
클라이언트1은 포털사이트나 회사의 메일 프로그램을 이용해서 메일 서버1로 메일을 보낸다.(STMP)
STMP를 사용하여 메일 서버 1에서 메일 서버 2로 메일을 전송한다.
메일 서버 2는 POP3를 사용하여 메일 서버2의 메일 박스에서 메일을 가져와 컴퓨터 2로 전송한다.
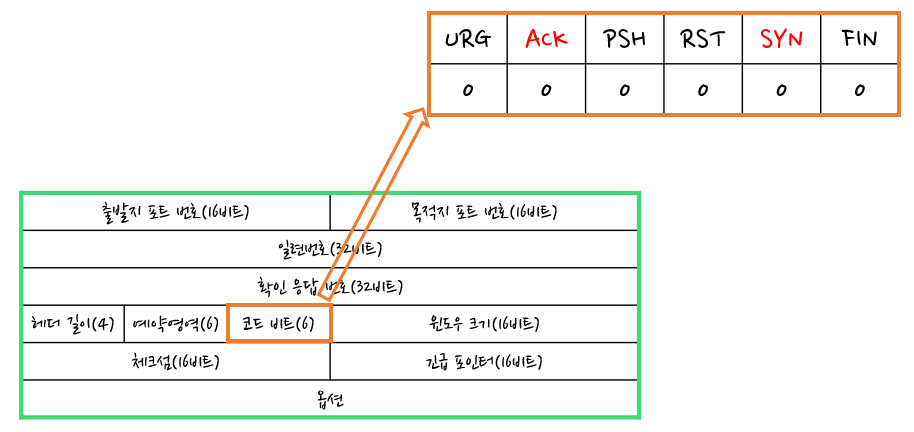
TCP는 신뢰성과 정확성을 우선으로 하는 연결형 통신 프로토콜이다. TCP 헤더를 붙여 세그먼트를 만드는 캡슐화 과정을 진행한다. 그리고 데이터를 전송하기 위해 필요한 가상의 독점 통신로를 확보하는 작업인 연결이라는 작업을 수행한다. 연결은 TCP 헤더의 코드비트 부분의 SYN와 ACK를 통해 3-way 핸드셰이크라고 하는 패킷 요청을 세 번 교환하는 행동을 하여 연결을 확립한다. 그리고 FIN와 ACK를 통해 4-way 핸드 셰이크를 진행해 연결이 끊어진다.
3-way 핸드셰이크를 통해 연결이 확보되어 실제 데이터를 보내거나 데이터를 받을 때에는 TCP 헤더의 일련번호(Sequence number)와 확인 응답 번호(Acknowledgement number)를 사용한다.
TCP 헤더
TCP는 데이터를 분할해서 보내는데 일련번호는 송신 측에서 수신 측에 이 데이터가 "몇 번 째 데이터인지" 알려 주는 역할을 한다. 즉, 전송된 데이터에 일련번호를 부여해 수신자는 원래 데이터의 몇 번째 데이터를 받았는지 알 수 있다.
확인 응답 번호는 수신 측이 몇 번째 데이터를 수신했는지 송신 측에 알려 주는 역할을 한다. 그래서 이 번호는 다음 번호의 데이터를 요청하는데 사용한다. 예를 들어, 10번 데이터를 수신하면 11번 데이터를 송신 측에 요청한다. 이 과정을 확인 응답이라고 한다.
데이터를 전송하기 전 단계에서 3-way 핸드셰이크로 연결 수입이 이루어지고 데이터를 전송하기 위해 이번 통신에 사용하는 일련번호인 3001번과 확인 응답 번호인 4001번으로 가정해보면
컴퓨터 1은 컴퓨터 2로 200바이트의 데이터를 전송한다.
컴퓨터 2는 200바이트를 수신하고 다음에 수신하고자 하는 데이터 번화를 확인 응답 번호에 넣는다. 다음에 수신하고자 하는 데이터는 3001+200=3201이므로 3201번부터 보내 달라고 요청한다.
컴퓨터 1은 컴퓨터 2로 3201번부터 200바이트의 데이터를 전송한다.
컴퓨터 2는 200바이트를 수신하고 다음에 수신하고자 하는 데이터의 번호를 확인 응답 번호에 넣는다. 다음에 수신하고자 하는 데이터는 3201+200=3401번부터 보내 달라고 요청한다.
위 과정을 데이터 전송이 완료될 때 까지 반복된다. 데이터가 항상 올바르게 전달되는 것은 아니므로 일련번호와 확인 응답 번호를 사용해서 데이터가 손상되거나 유실된 경우에는 같은 데이터를 재전송하게 되어 있는데 이것을 재전송 제어라고 한다.
윈도우 크기란?
위에서 설명한 과정은 세그먼트(데이터) 하나를 보낼 따마다 확인 응답을 한 번 반환하는 통신이라서 비효율적이다. 위 방식 대신에 매번 확인 응답을 기다리는 대신 세그먼트 연속해서 보내고 난 다음에 확인 응답을 반환하면 효율이 높아진다.
수신 측에서 받은 세그먼트를 일시적으로 보관하는 장소가 있는데 그 장소를 버퍼(Buffer)라고 한다. 이 버퍼 덕분에 세그먼트를 연속해서 보내도 수신 측은 대응할 수 있고 확인 응답의 효율도 높아진다. 하지만, 세그먼트를 대량으로 받아 버퍼가 처리하지 못하는 경우가 생기는데 이 현상을 오버플로(Over flow)라고 한다.
그래서 오버플로가 발생하지 않도록 버퍼의 한게 크기를 알고 있어야 하는데 그것을 TCP 헤더에서 윈도우 크기 값에 해당한다. 윈도우 크기(Window size)는 얼마나 많은 용량의 데이터를 저장해 둘 수 있는지를 나타낸다. 즉, 확인 응답을 일일이 하지 않고 연속해서 송수신할 수 있는 데이터의 크기를 말한다.
그럼 송수신측은 서로의 윈도우 크기를 어떻게 확인할 수 있을까? 바로 3-way 핸드셰이크를 할 때 판단한다.
컴퓨터2는 컴퓨터 1의 윈도우 크기가 3000이라는 것을 알게 되며 컴퓨터1은 컴퓨터 2의 윈도우 크기가 2000이라는 것을 알게 된다.
오른쪽과 같은 방식으로 수신 측이 윈도우 크기를 가지고 있다면 확인 응답을 받지 않고도 세그먼트(데이터)를 연속적으로 전송할 수 있다.
포트 번호란?
전송 계층에서 연결 확립, 재전송 제어, 윈도우 제어 등과 같은 기능에 의해 TCP는 데이터를 정확하게 전달할 수 있었다. 전송 계층은 데이터를 정확하게 전달하는 기능뿐만 아니라 전송된 데이터의 목적지가 어떤 애플리케이션(웹 또는 메일 등)인지 구분하는 역할도 수행한다.
목적지가 어떤 애플리케이션인지 구분하지 못하는 것을 방지하기 위해서는 출발지 포트 번호(Source port number)와 목적지 포트 번호(Destination port number)가 필요하다.
포트 번호는 0~65535번을 사용할 수 있는데 0~1023번은 주요 프로토콜이 사용되도록 예약되어 있으며 잘 알려진 포트(Well-known ports)라고 한다. 1024번은 예약되어 있지만 사용되지 않는 포트이고, 1025번 이상은 랜덤 포트라고 해서 클라이언트 측의 송신 포트로 사용된다. 아래 표에 해당하는 포트번호는 서버에서 주로 사용되는 애플리케이션 번호이다.
이처럼 동작하는 애플리케이션은 각각 포트번호가 있어서 다른 애플리케이션과 서로 구분된다. 데이터를 전송할 때는 상대방의 IP 주소가 필요하지만, 어떤 애플리케이션이 사용되고 있는지 구분하려면 TCP는 포트 번호가 필요하다.
UDP란?
UDP는 TCP와 다르게 비연결형 통신으로 데이터를 전송할 때 TCP 처럼 시간이 걸리는 확인 작업을 일일이 하지 않는다. 또한, 신뢰성과 정확성을 중요시 한 TCP와는 다르게 UDP는 효율성을 중요시 한다.
UDP의 장점은 데이터를 효율적으로 빠르게 보내는 것이라서 스트리밍 방식으로 전송하는 동영상 서비스와 같은 곳이 사용된다. 동영상을 TCP로 전송하게 되면 수신 확인하는 데 시간이 너무 오래 걸려서 동영상을 원활하게 볼 수 없다.
TCP는 TCP 헤더가 붙은 데이터를 세그먼트라고 했는데 UDP 에서는 UDP 헤더가 붙은 데이터를 UDP 데이터그램이라고 한다. UDP 헤더는 올바른 목적지의 애플리케이션으로 데이터를 전송하기 위해 필요한 정보가 기록되어 있다.
또한 UDP를 사용하면 랜에 있는 컴퓨터나 네트워크 장비에 데이터를 일괄로 보낼 수 있다. 이것을 브로드캐스트(Broadcast)라고 하는데 브로드캐스트는 목적지에 관계없이 랜에서 일괄적으로 통보를 보낼 수 있어 가능하다. TCP는 3-way 핸드셰이크와 같이 데이터를 전송할 때도 확인 응답을 하나씩 보내야 하기 때문에 브로드캐스트와 같이 불특정 다수에게 보내는 통신은 적합하지 않을 뿐더러 목적지를 지정하지 않으면 안 되기 때문에 일괄 통신을 할 수 없다.
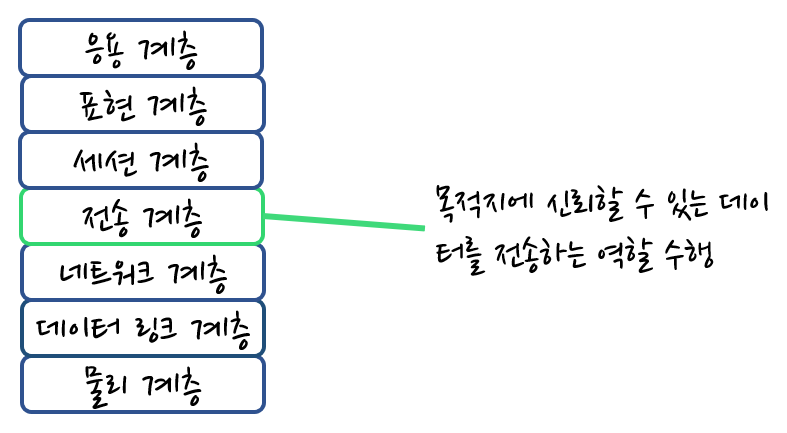
물리 계층, 데이터 링크 계층, 네트워크 계층 이 세 개의 계층만 있으면 목적지에 데이터를 보낼 수 있다. 하지만, 데이터가 손상되거나 유실되면 이 세 개의 계층에서는 아무것도 해줄 수 없다.
이를 방지해주는 역할은 OSI 모델에서 전송 계층이 수행한다. 전송 계층은 목적지에 신뢰할 수 있는 데이터를 전달하기 위해 필요하다.
전송 계층에는 오류를 점검하는 기능이 있는데, 오류가 발생하면 데이터를 재전송하도록 요청한다. 또한, 전송된 데이터의 목적지가 어떤 애플리케이션인지 식별하는 기능을 가지고 있다. 예를 들어, 웹에서 사용하는 데이터인데 메일 프로그램에 전송하는 것을 방지해준다.
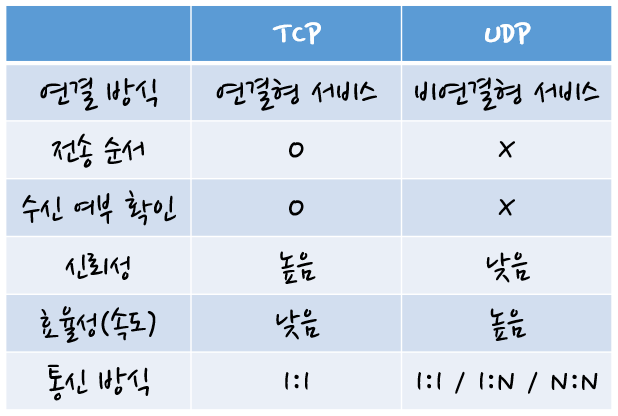
연결형 통신과 비연결형 통신
전송 계층의 특징을 간단히 설명하면 신뢰성/정확성과 효율성으로 구분할 수 있다.
신뢰성/정확성은 데이터를 목적지에 문제없이 전달하는 것이고, 효율성은 데이터를 빠르고 효율적으로 전달하는 것이다. 이렇게 신뢰할 수 있고 정확한 데이터를 전달하는 통신을 연결형 통신이라고 하고, 효율적으로 데이터를 전달하는 통신을 비연결형 통신이라고 한다.
그렇다면 신뢰성과 정확성이 보장되지 않는 비연결형 통신은 보통 언제 쓰일까? 동영상을 볼 때 많이 사용한다. 동영상은 신뢰할 수 있고 정확한 데이터 전송보다는 빠른 전송이 필요하기 때문이다. 데이터가 늦게 도착해서 화면이 버벅거리는 동영상보다는 데이터가 조금 유실되더라도 원활하게 보는 것이 좋다.
또한, 연결형 통신 프로토콜에는 TCP가 사용되고, 비연결형 통신 프로토콜에는 UDP가 사용된다.
TCP란
데이터 링크 계층에서 이더넷 헤더를 붙여 프레임을 만들고 네트워크 계층에서 IP 헤더를 붙여 IP 패킷을 만든 것처럼 전송 계층에서도 TCP 헤더를 붙여 세그먼트(Segment)를 만드는 캡슐화를 진행한다.
TCP는 연결형 통신에 사용한다. 연결형 통신은 꼼꼼하게 상대방을 확인하면서 데이터를 전송해야 하는데 그 전에 해야할 일은 연결(Connection)이라는 가상의 독점 통신로를 확보해야 한다.
※ 연결(Connection): TCP 통신에서 정보를 전달하기 위해 사용되는 가상의 통신로이며 연결을 확립하고 데이터를 전송한다.
연결을 확립하기 위해서는 TCP 헤더의 코드 비트를 확인해야 한다. 코드 비트는 연결의 제어 정보가 기록되는 곳이다. 코드 비트 중에서도 연결 요청을 뜻하는 SYN와 확인 응답을 뜻하는 ACK이 중요하다.
3-way 핸드 셰이크
연결(Connection)은 SYN와 ACK를 사용하여 확립할 수있다. 신뢰할 수 있는 연결을 하려면 데이터를 전송하기 전에 패킷을 교환하는데 다음과 같이 세 번 확인 한다.
통신을 하려면 컴퓨터2에게 허가를 받아야 하므로, 컴퓨터1에서 연결 확립 허가를 받기 위한 요청(SYN)를 보낸다.
컴퓨터2는 컴퓨터1이 보낸 요청을 받은 후에 허가한다는 응답을 회신하기 위해 연결 확립 응답(ACK)를 보내고 동시에 컴퓨터1에게 데이터 전송 허가를 받기 위해 연결 확립 요청(SYN)를 보낸다.
컴퓨터2의 요청을 받은 컴퓨터1은 컴퓨터2로 허가한다는 응답으로 연결 확립 응답(ACK)을 보낸다.
이처럼 데이터를 보내기 전에 연결을 확립하기 위해 패킷 요청을 세 번 교환하는 것을 3-way 핸드 셰이크(three-way handshake)라고 한다.
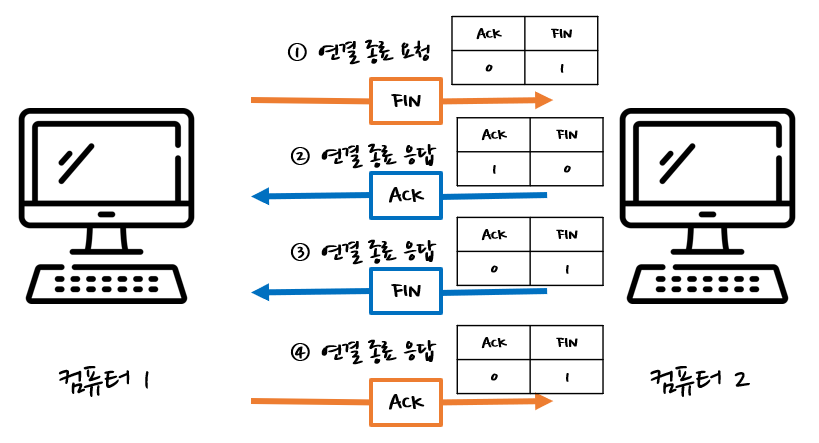
연결을 끊을 때에는 FIN와 ACK를 사용하여 확립할 수있다. FIN은 연결 종료를 뜻한다. 이처럼 연결을 종료하기 위해 패킷 요청을 네 번 교환하는 것을 4-way 핸드 셰이크(four-way handshake)라고 한다.