이더넷(Ethernet)이란 무엇인가?
데이터 링크 계층은 네트워크 장비 간에 신호를 주고 받는 규칙을 정하는 계층으로, 랜에서 데이터를 정상적으로 주고받기 위해 필요한 계층이다. 그 규칙들 중 일반적으로 많이 사용되는 규칙이 이더넷(Ethernet)이다. 즉, 랜에서 적용되는 규칙이다.

이더넷은 허브와 같은 장비에 연결된 컴퓨터와 데이터를 주고 받을 때 사용한다. 하지만 허브는 전기 신호를 전달받을 포트뿐만 아니라 나머지 포트에도 전달한다는 문제점이 있다. 관계없는 다른 컴퓨터들도 데이터를 받으면 곤란한 상황이 발생할 수 있다.
이러한 경우를 대비해 규칙을 정해둔다. 데이터에 목적지 정보를 추가해서 보내 목적지 이외의 컴퓨터는 데이터를 받더라도 무시하도록 말이다.

또한, 컴퓨터 여러 대가 동시에 데이터를 보내면 데이터들이 서로 부딪히는 충돌(collision)이 발생할 수 있다.

이더넷은 데이터를 보내는 시점을 늦춰서 충돌을 방지하기 위한 구조로 설계되어 있다.

이러한 기법을 CSMA/CD라고 하는데 정의는 다음과 같다.
- CS: 데이터를 보내려고 하는 컴퓨터가 케이블에 신호가 흐르고 있는지 아닌지를 확인하는 규칙
- MA: 케이블에 데이터가 흐르고 있지 않다면 데이터를 보내도 좋다는 규칙
- CD: 충돌이 발생하고 있는지를 확인하는 규칙
하지만, 스위치(Switch)라는 네트워크 장비가 등장하면서 CSMA/CD는 거의 사용하지 않게 되었다.
MAC 주소란 무엇인가?
랜 카드는 비트열(0과 1)을 전기 신호로 변환한다. 이러한 랜 카드에는 MAC 주소라는 번호가 정해져 있는데, 이는 제조할 때 새겨지기 때문에 물리 주소라고 불리고 전 세계에서 유일한 번호로 할당되어 있다. MAC 주소는 48비트(6 바이트) 숫자로 구성되어 있으며, 그 중 앞 쪽 24비트는 랜 카드를 만든 제조사 번호이고 뒤 쪽 24비트는 제조사가 랜 카드에 붙인 일련 번호이다. 앞, 뒤쪽 모두 정해진 규칙이 있기 때문에 중복되지 않는다.
네트워크 통신에서 송신할 때에는 OSI 모델이나 TCP/IP 모델에서 필요한 정보를 헤더에 담아 데이터에 붙여나가는 작업인 캡슐화를 진행한다. OSI에서는 데이터 링크 계층, TCP/IP에서는 네트워크 계층에 해당하는데, 이 계층에서 이더넷 헤더와 트레일러를 붙이게 된다.
이더넷 헤더는 목적지의 MAC 주소(6 바이트), 출발지의 MAC 주소(6 바이트), 유형(2 바이트) 총 14바이트로 구성되어 있다.
여기서 유형은 이더넷으로 전송되는 상위 계층 프로토콜의 종류를 나타낸다.

그리고 트레일러는 FCS(Frame Check Sequence)라고도 하는데, 데이터 전송 도중에 오류가 발생하는지 확인하는 용도로 사용한다.
이처럼 이더넷 헤더와 트레일러가 추가된 데이터를 프레임이라고 한다. 이 프레임은 네트워크를 통해 전송된다.

MAC 주소를 통한 프레임 전송 과정
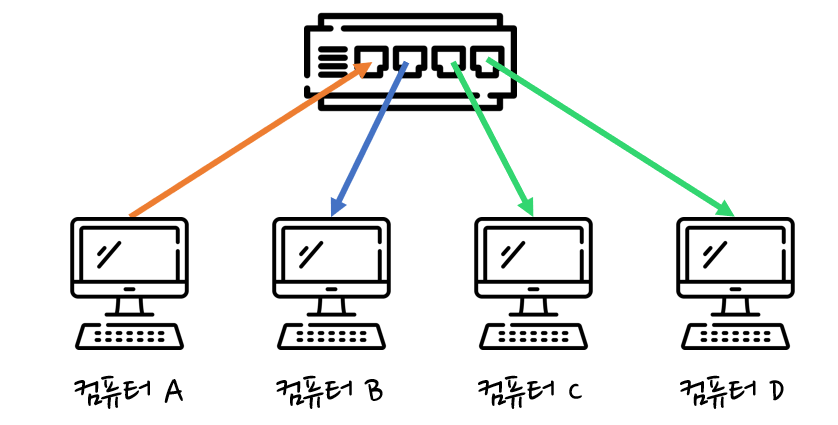
아래 그림과 같이 컴퓨터 A에서 컴퓨터 B로 데이터 전송한다고 가정하면 이더넷 헤더에 목적지인 컴퓨터 B의 MAC 주소와 근원지인 컴퓨터 A의 MAC 주소 정보를 담는다. 그 후에 데이터에 이더넷 헤더와 트레일러를 추가하는 캡슐화 과정을 거쳐 프레임을 만들고 물리 계층에서 이 프레임 비트열을 전기 신호로 변환하여 네트워크를 통해 전송한다.
허브를 예로 들면 컴퓨터 A가 보낸 데이터를 컴퓨터 B~D에 다 전송하지만 컴퓨터 C, D는 이더넷 헤더에 붙어 있는 목적지 MAC 주소와 자신의 MAC 주소가 다르기 때문에 데이터를 파기한다. 컴퓨터 B는 목적지 MAC 주소와 자신의 MAC 주소가 일치하므로 데이터를 파기하지 않고 역캡슐화를 진행한다. 컴퓨터 B는 역캡슐화를 한 다음에 데이터를 수신한다.

컴퓨터 A와 컴퓨터 C 동시에 컴퓨터 B로 데이터를 전송한다면 충돌이 발생할 것이다. 충돌을 방지하기 위해 CSMA/CD 규칙을 사용할 수 있다.
스위치의 구조
스위치는 데이터 링크 계층에서 동작하며 레이어 2 스위치 또는 스위칭 허브라고 불린다. 겉모습만 봐서는 허브와 구별하기 힘들지만 허브와 다르게 데이터 충돌을 방지할 수 있다.

스위치 내부에는 MAC 주소 테이블(Mac Address Table)이 존재하는데 이 MAC 주소 테이블은 스위치의 포트 번호와 해당 포트에 연결되어 있는 컴퓨터의 MAC 주소가 등록되는 데이터베이스이다.
맨 처음 전원을 킨 스위치 MAC 주소 테이블에는 아무것도 등록되어 있지 않지만 MAC 주소가 추가된 프레임이라는 데이터가 전송되면 MAC 주소 테이블에 포트 번호와 함께 추가가 된다. 만약 이미 등록되어 있는 MAC 주소라면 건너 뛴다. 이를 MAC 주소 학습 기능이라고 한다.
하지만 스위치도 피할 수 없는 것이 있다. MAC 주소 테이블에 MAC 주소가 등록되어 있지 않다면 허브와 같이 등록되어 있지 않은 포트 번호에 모두 전송된다는 것이다. 이를 플러딩(Flooding)이라고 부른다.

만약 MAC 주소 테이블에 컴퓨터 B의 MAC 주소가 등록되어 있고 컴퓨터 B로 데이터를 전송한다고 가정한다면 목적지 컴퓨터인 컴퓨터 B로만 전송하게 된다. 이를 MAC 주소 필터링이라고 한다. 즉, 불필요한 데이터를 네트워크에 전송하지 않게 되는 것이다.

그렇다면 지금의 MAC 주소 테이블 상태에서 만약 컴퓨터 A에서 컴퓨터 C로 데이터를 보낸다고 가정하면 어떻게 될까? MAC 주소에 해당 포트 번호의 목적지 MAC 주소가 없기 때문에 다시 플러딩이 발생한다.
데이터가 케이블에서 충돌하지 않는 구조
통신 방식에는 전이중 통신 방식과 반이중 통신 방식이 있다. 전이중 통신 방식은 데이터의 송, 수신을 동시에 통신하는 방식이고 반이중 통신 방식은 회선 하나로 송신과 수신을 번갈아가면서 통신하는 방식이다.
아래 그림과 같이 컴퓨터 1과 컴퓨터 2를 직접 랜 케이블로 연결한다면 선을 네 쌍을 사용하기 때문에 전이중 통신 방식이 된다.

반면 허브 내부에는 송, 수신이 나누어져 있지 않기 때문에 컴퓨터 A와 B를 허브로 연결하면 동시에 데이터를 보낼 때 충돌이 난다. 이처럼 허브를 사용하면 회선 하나를 송신과 수신이 번갈아가면서 사용하는 반이중 통신 방식을 사용하게 된다.

스위치는 충돌이 일어나지 않는 구조로 되어 있기 때문에 전이중 통신 방식으로 데이터를 주고 받을 수 있다. 이처럼 허브를 사용하면 충돌로 인한 네트워크 지연이 발생하기에 최근에는 네트워크로 스위치를 사용한다.

충돌 도메인
충돌 도메인(Collision damain)은 충돌이 발생할 때 그 영향이 미치는 범위를 말한다. 허브와 스위치를 예로 들면 허브는 충돌의 영향이 모든 컴퓨터에 미치고 스위치는 전이중 통신 방식이며 접속되어 있는 모든 컴퓨터 영향을 미치지 않기에 충돌이 발생하지 않고 충돌 도메인의 범위도 컴퓨터 하나하나로 좁아진다.


'네트워크 > 기초' 카테고리의 다른 글
| 6. 네트워크 계층 - 1 (목적지에 데이터 전달) (0) | 2020.10.07 |
|---|---|
| 5. ARP(데이터 링크와 네트워크의 다리) (0) | 2020.10.06 |
| 3. 물리 계층(데이터를 전기적 신호로 변환) (0) | 2020.09.28 |
| 2. 네트워크 통신 규칙 (0) | 2020.09.21 |
| 1. 네트워크란? (0) | 2020.08.26 |